이 포스트는 AWS로는 잘못된 사용으로 사고를 치고 Go라고는 써본 적도 없는 제가 인턴으로 구르면서 던져진 과제를 해결하는 과정을 담은 포스트입니다. 포스트의 내용이 부적절 할 수 있음을 미리 말씀드립니다.
왜 Go?
회의중 : 아무튼 C++이나 자바는 쓰기에 문법이 그렇고 Python은 느리다 -> Go를 쓰기로 했습니다
솔직한 감상으로는 어차피 쿼리를 보낸 후에 처리하는 작업은 redshift에서 해주는데 쿼리를 구성해서 보내줄 뿐인 프로그램의 처리속도가 과연 redshift의 처리속도에 비해 어느정도의 bottleneck이 되는가에 대해서는 회의적이네요
절대 Python이 편해서 투덜거리는게 아니에요 아무튼 그래요
그리고 데이터가 커지면 과연 lambda의 처리로 그 데이터를 감당할 수 있는가도 의문이지만 이건 짜두고 여차하면 lambda가아니라 서버에서 처리하게 바꿀 수 있겠지요
Redshift는 Free tier 와 Cluster 생성 시 선택 가능한 ( Free tier에서는 그냥 들어가는 ) Sample data를 사용하겠습니다
Redshift는 1달 750시간 2달무료제공합니다 ( 2달 동안 켜둬도 괜찮다는 뜻 )
AWS Redshift API
원래는 lib/pq를 이용하여 외부에서 Access하려 했는데 아마존에서 제공하는 aws redshift api 들이 존재했다.
lib/pq를 이용한 접속은 여러 세큐리티, 네트워크 설정과 redshift의 public access 공개 ( 또는 같은 VPC내부 서버에서의 사용 ) 등등이 필요하기도 하니 이 API가 더 타당할지도 모른다.
Redshift Dat API 문서 ( 아래 링크 ) 에 들어가면 기본적인 틀이 제공되어 있다.
Input 과 response의 타입이 정의되어있고 각 명령별로 가장 아래의 See Also 에는 지원하는 언어별로 구체적인 예시가 있다.
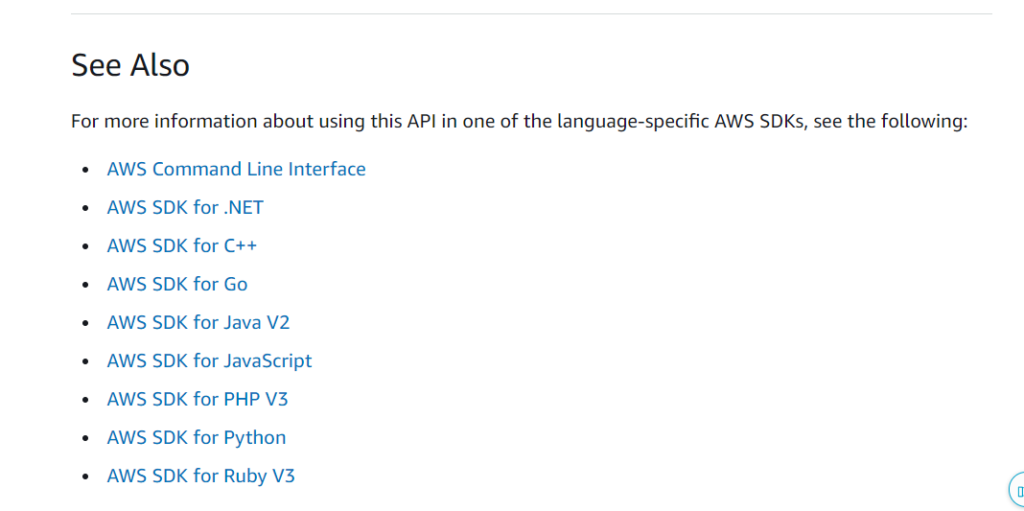
Python에 비하면 Go의 문서가 불친절하게 느껴진다 ㅜㅜ
response = client.execute_statement(
ClusterIdentifier='string',
Database='string',
DbUser='string',
Parameters=[
{
'name': 'string',
'value': 'string'
},
],
SecretArn='string',
Sql='string',
StatementName='string',
WithEvent=True|False
)
func (c *RedshiftDataAPIService) ExecuteStatement(input *ExecuteStatementInput) (*ExecuteStatementOutput, error)
위가 python의 문서고 아래가 go의 문서이다. Python은 보자마자 필요에 맞게 바꿔서 쓰겠는데 Go는 파라미터에대한 설명도 없고 이게 뭘까 일단 go부터 공부를 더 해야하나보다
아무튼 이 Spec을 해석해보자
보고왔다 이번 경우에 크게 도움이 된 것 같지는 않다 func (c *RedshiftDataAPIService) ExecuteStatement(input *ExecuteStatementInput) (*ExecuteStatementOutput, error)
이게 과연 뭘 해달라는 걸까
먼저 Golang의 Function declarations와 Method declaration s를 봤다.
음 각 부분들 명칭과 구조는 알겠고 이 것은 Method declaration 인 것 같다.
func (p *Point) Length() float64 {
return math.Sqrt(p.x * p.x + p.y * p.y)
}
func (p *Point) Scale(factor float64) {
p.x *= factor
p.y *= factor
}
역시 예시가 가장 알기 편하다
- func : 함수임
- (c *RedshiftDataAPIService) : Receiver
- ExecuteStatement : 이름
- (input *ExecuteStatementInput): Parameter
- (*ExecuteStatementOutput, error) : Signature
즉 RedshiftDataAPIService형 포인터 c와 ExecuteStatementInput형 포인터 input을 받아서 ExecuteStatementOutput형 포인터와 error형을 return한다는 뜻인 것 같다.
아마 ExecuteStatementInput안에 쿼리문과 같은 필요한 내용이 있을 것 같다.
*RedshiftDataAPIService
type RedshiftDataAPIService struct {
*client.Client
}
보고 이게 뭔가 싶었다
func New(p client.ConfigProvider, cfgs ...*aws.Config) *RedshiftDataAPIService
New라는 function이 알아서 잘 맞춰서 return해주는 것 같다. 페이지 에 Example이 포함되어 있으니 경우에 맞춰서 사용해주면 될 것 같다.
*ExecuteStatementInput
구조체이며 다음과 같은 내용들을 포함한다. ( 링크)
- ClusterIdentifier : 클러스터 이름
- Database : 데이터베이스 이름
- DbUser : 데이터베이스 사용자 이름
- SecretArn : 데이터베이스 접근용 Arn
- Sqls : 쿼리들, 최소 1 이상의 string list
- WithEvent : Amazon EventBridge에 event정보를 보낼지 안 보낼지
*ExecuteStatementOutput
return 값의 구조이다 ( 링크)
- ClusterIdentifier : 클러스터 이름
- Database : 데이터베이스 이름
- DbUser : 데이터베이스 사용자 이름
- Id : SQL의 result가 fetch될 ID -> 실제 동작에서 확인해야 겠다.
- SecretArn : 데이터베이스 접근용 Arn
Lambda용으로 적절한 IAM 설정하기
회사 AWS 관리자 분에게 부탁해서 IAM 설정권한을 받아왔다.
아직은 스타트업이라 권한 구조가 확립되지 않은 상태라서 종종 이런 조절이 필요해질 것 같다
다만 권한을 풀로 개방하고 줄이는 것 보다 최대한 빡빡하게 걸고 하나하나 필요한 부분을 풀어가는 것이 맞는 것 같다.
IAM Policy에는 Redshift에 Write의 Get Cluster Credential에 대한 권한이 필요하며 Redshift Data API는 자신이 사용할 기능에 맞춰서 제한을 걸어 줄 필요가 있다.
이 문서는 Redshift Get Cluster Credential 과 Redshift Data API Full access를 기반으로 진행하겠습니다.
권한을 테스트하기 위해서 먼저 이 블로그(일본어)의 sample code를 python runtime으로 실행시켜서 정상적으로 결과가 나오는 것을 확인했다. 현재 블로그에 적힌 Docker의 설정은 불필요하다.
 안녕
안녕
코드확인
Golang의 활용에 관해서는 자료가 많지 않지만 다행히 공식 quickstart 자료 가 있었다.
기본적인 구조는 쿼리를 셋팅하고 event를 받아서 redshift에의 연결에 필요한 값들을 받는다.
이후 ExecuteStatement에서 ExecuteStatementInput을 입력한다. 이 입력은 event에서 제공한 JSON을 Parsing하여 구성된다. Return을 execstmt_req에 받아서 이 Statement처리에대한 Describe를 요청한다. 이 때 ID가사용되는 것 같다.
DescribeStatemnetOutput 에는 사용한 클러스터, 데이터베이스, statement가 실행된 시간과 소요시간과 결과 그리고 상태등등의 데이터가 있다.
이 중에서 상태로부터 처리가 끝났는지 안끝났는지를 확인하고 실패시 설정된 기간만큼 재시도를 해본다.
각각의 기능은 명확하지만 생각했던 것 보다는 연계가 복잡하여 샘플코드없이 처음부터 치는 것은 솔직히 토나오는 작업일 것 같았다.
먼저 샘플코드를 GOOS를 linux상태로해서 ( linux가 아니면 에러발생. go env 에서 GOOS 항목 확인하기 )
go build -o <파일명> <코드파일이름.go> 로 컴파일하여 압축한 뒤 lambda에 올린다.
Test에서 다음과 같은 body를 만들어주자
{
"redshift_cluster_id": "클러스터명",
"redshift_database": "데이터베이스이름 -> sample data의경우는 dev",
"redshift_user": "유저명 : 아마 기본은 awsuser",
"redshift_iam_role": "s3권한이 있는 IAM ROLE",
"run_type": "synchronous나 asynchronous중 하나"
}

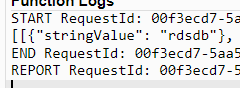
성공했다고 나온다.
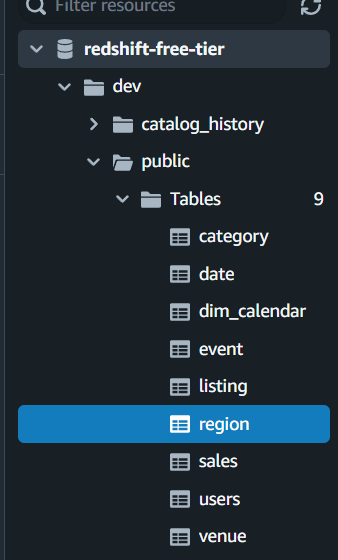
쿼리에디터로 확인시 public Tables에 region이 추가되어있다
후기
이제 이 코드를 회사에서 요구한 스펙에 맞게 수정하는 작업을 해야겠다.
사실 구글에는 수만은 예제코드들이 있고 대부분의 일들은 이 예제코드를 수정하는 것만으로도 해결할 수 있다.
그래서 종종 과연 그 예제코드들을 활용하는게 맞는건가 너무 날먹아닌가 싶은 생각을 하는데 생각해보면 본인이 직접짜서 그것보다 잘 짤 자신 없으면 예제코드를 활용하여 빠른 작업이라도 하는게 맞는 것 같다.
특히 공식예제보다 잘 짜기는 절대 쉽지 않을 것이라고 생각하기도 하고..