도대체 뭘 하는데 맨날 데이터, 데이터베이스 AWS와 씨름을 하는지 설명을 안했던 것 같네요
인턴 일이 프론트 담당 분이 들어오면서 저는 영업자료용 프론트 껍데기 개발에서 백엔드로
넘어갔습니다
통합 데이터 카탈로그 제작을 위해서는 기업의 다양한 DB 서비스에 연결해서 각 데이터들의
메타데이터를 확보할 필요가 있습니다.
그 중 Redshift에 접속하여 해당 데이터를 직접 가져오지 않으면서도 종합적인 데이터는 가져와야하는
Redshift Connector제작을 담당하고 있습니다.
이번에는 데이터의 왜도와 첨도 (Skewness and Kurtosis)를 계산하는데 문제가 생겼습니다.
간단하게 말하자면 왜도는 비대칭도로 데이터가 얼마나 치우쳐졌는지를 계산하며
첨도는 그 정점이 주위에비해 얼마나 튀어나와있는지 ( 주위에서 외곽으로의 경사)
를 나타내는 수치입니다.
어디 이런 예시 그래프 첨부할 수 있는 저작권Free한 자료 없나..
정규분포상의 모집단에 대해 왜도와 첨도는 다음과 같이 계산합니다.
첨도는 3을 기준으로 생각하기에 아래에는 초과첨도에 대한 식입니다.
- 왜도
[latex]E[\left(\frac{X-\mu}{\sigma}\right)^3] [/latex]
- 초과첨도
[latex]E[\left(\frac{X-\mu}{\sigma}\right)^4]-3 [/latex]
아니 수식 왜이리 작게나와…
아무튼 문제는 이 평균의 평균에 있습니다. 예를들면 (어느값-평균)의 평균을 계산하고 싶다고 해봅시다.
SELECT AVG(dateid) as avg, AVG(dateid-avg) FROM “public”.“sales”
그 결과는
ERROR: aggregate function calls may not have nested aggregate or window function
즉 Window function안에 Window function이 못 들어간다 -> AVG안에서 avg의 값을 사용할 수 없다
라는 에러가 발생한다.
avg값을 받은 다음에 다시 쿼리를 보내기에는 Table에 접근을 2번해야하여 비효율적이다.
안 그래도 모든 Table을 돌면서 모든 숫자형 Column에대해 받아와야해서 무거운 쿼리를
두번씩이나 접근하게 할 수는 없다.
데이터를 가져와서 백엔드상에서 계산해서 넣을 수 있으면 편리하고 Redshift의 부담도 줄일 수 있지만
이 프로그램상에 데이터의 직접적인 값이 들어와서는 안된다. (데이터 보호 및 보안 차원)
수식을 전개해본 결과 충분히 가능하다는 사실을 깨달았다.
우리가 분산을 계산할 때 (제곱의 평균) - (평균의 제곱)과 같은 개념이다.
- 왜도
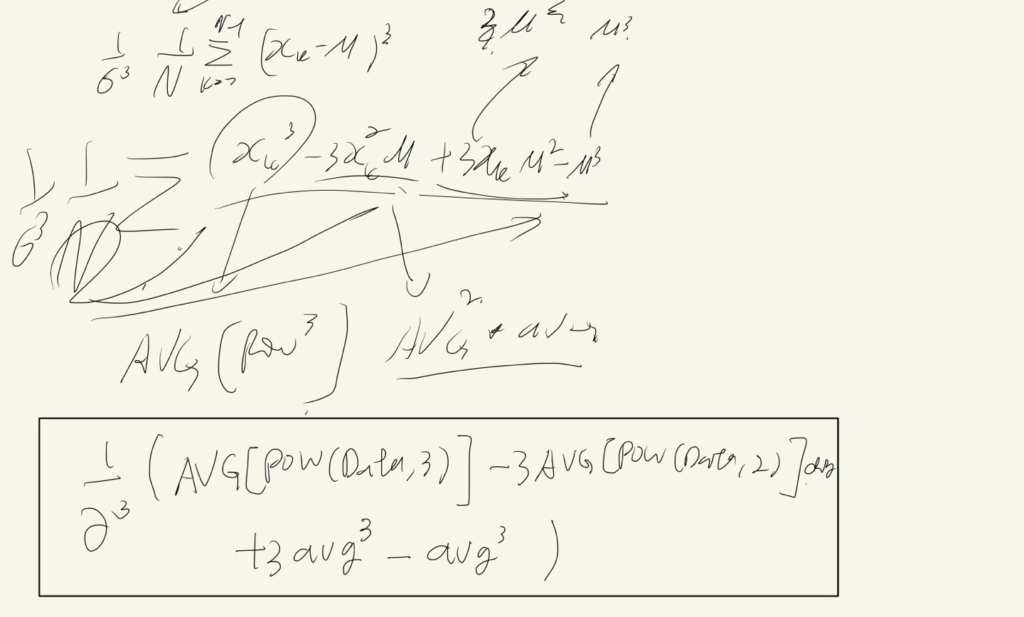
에벱의 악필 대공개시간이다. Window function과 math function은 포함 관계를 가질 수 있으며 window function끼리의 연산 또한 괜찮다.
- 첨도
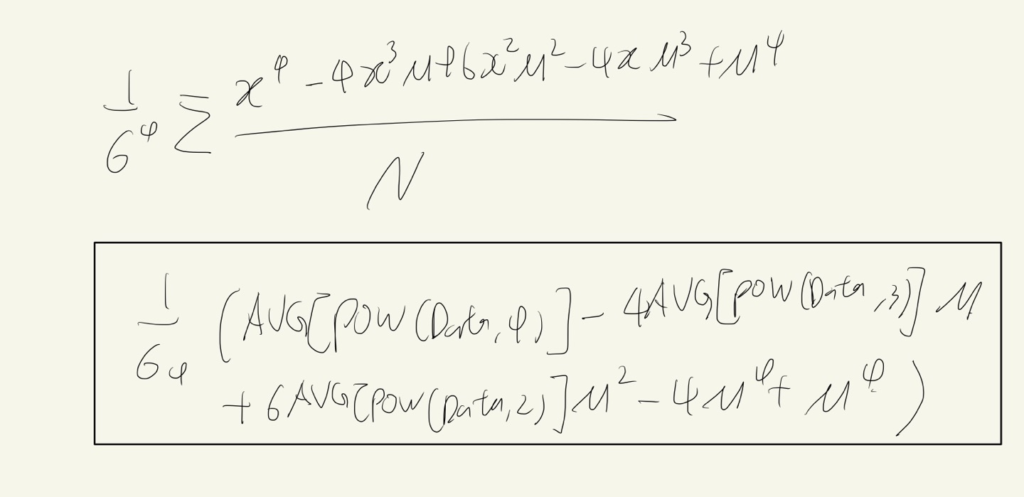
오~~ 이제 이걸 실제로 쿼리로 계산해봐야겠다.
첨도를 계산했더니 정신나간 값이 나왔다.. 자연증가하는 dateid에 대해 계산하니 어찌보면 당연한 결과다 좀 더 그럴싸한 데이터를 모셔와야겠다.
sales의 pricepaid라는 좋은 지표를 놔두고 난 뭘했던거지?? 참고로 사용 데이터는 redshift의 sampledata 입니다.
SELECT
MEDIAN(pricepaid),
CAST(STDDEV(pricepaid) as dec(15,3)) as std,
AVG(pricepaid) as avg,
CAST((AVG(pricepaid^3)-3*AVG(pricepaid^2)*avg+2*avg^3)/(std^3) as dec(10,3)) as skew,
CAST((AVG(pricepaid^4)-4*AVG(pricepaid^3)*avg+6*AVG(pricepaid^2)*avg^2-3*avg^4)/(std^4) as dec(10,3))-3 as kurt
FROM "public"."sales"

첨도가 좀 많이 크다.. 데이터가 정규분포와는 거리가 먼 친구인 것 같다.
이하는 검증을 위한 뻘짓 기록
SELECT COUNT(*), pricepaid FROM sales GROUP BY pricepaid ORDER BY pricepaid
위의 쿼리로 확인하고 redshift의 chart기능으로 뽑아본 결과
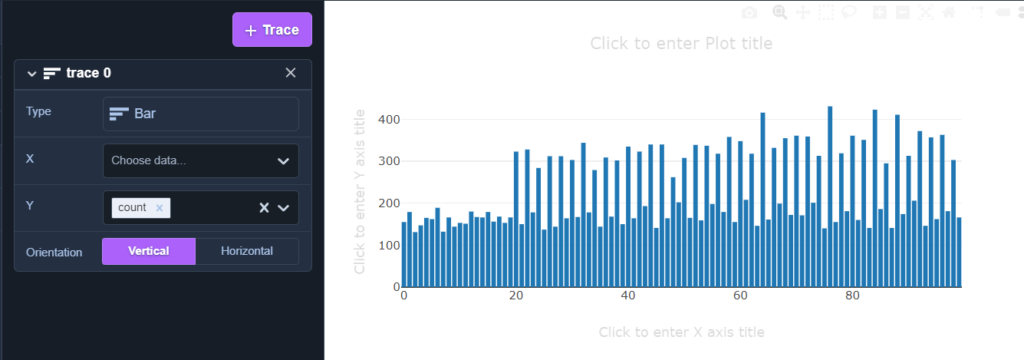 이걸론 정상적인 결과가 나올 수가 없다.
이걸론 정상적인 결과가 나올 수가 없다.
이래서는 이 식의 검증을 할 수가 없다 정규분포 데이터가 필요하지만 redshift는 postgresql의 normal_rand 함수를 지원하지 않는다
이쯤에서 현타가 온다. 이게 과연 가치있는 통계자료인가??
DB과제에서 친구 정보를 입력하라고 했을 때 친구가 한명도 없어서 도움을 받았던 Mockaroo 를 꺼냈다
대충 자바스크립트의 faker같은 가짜 데이터 생성기이다.
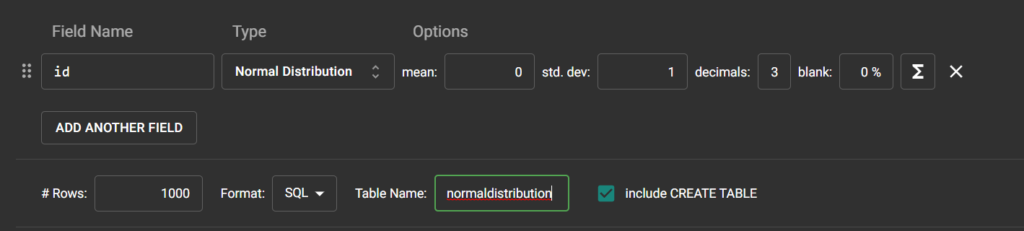
이렇게 셋팅해서
 다운로드 해주면!
다운로드 해주면!
쿼리를 복붙하면 된다
아니다!! 레드쉬프트에는 그대로 복사하면 안된다!!!!! 수업의 일반 postgresql과 헷갈렸다
create table normaldistribution (
id DECIMAL(2,1)
);
insert into normaldistribution (id) values (-0.3),
(-1.4),
(0.0),
(-0.1),
(-2.2),
(2.5),
(-0.0),
(-1.1),
이하 생략
위와 같은 느낌으로 바꿔줘야한다.. 안그러면 Result가 1000개까지 올라가는 것을 볼 수 있다.
이번엔 안썼지만 이럴 때에 정규표현식은 정말 유용하다
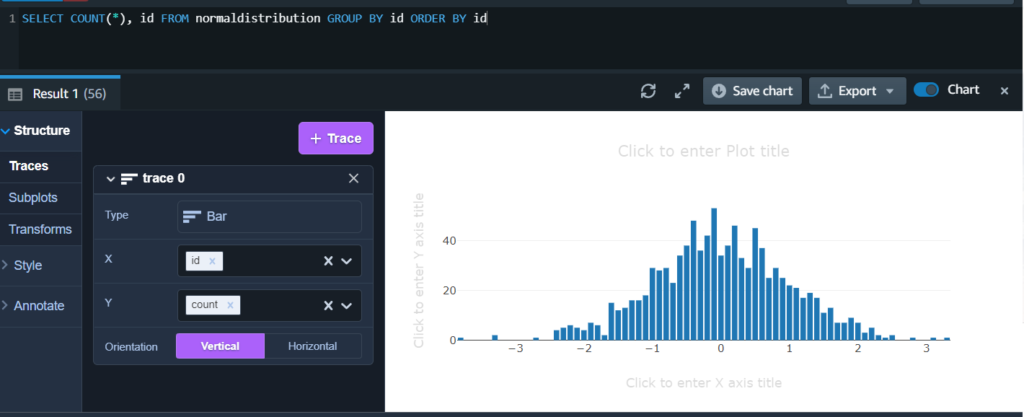
이제야 데이터 같은 무언가가 나왔다.
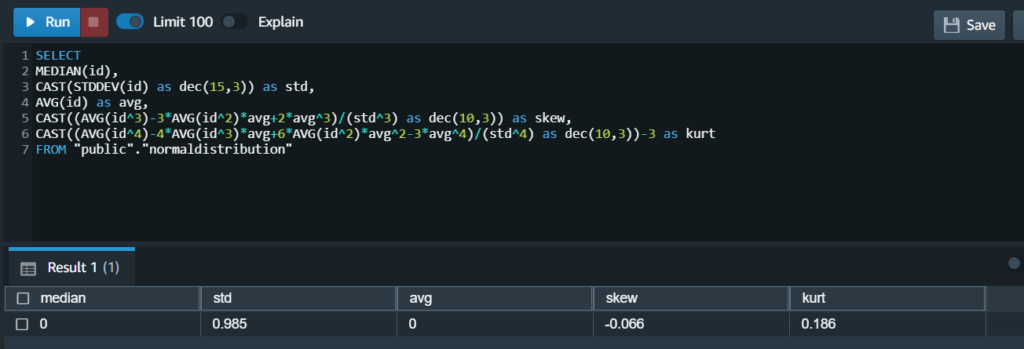
테스트 결과도 괜찮은 것 같다.
다만 이 통계자료의 실효성에 관해서는 한번 회의가 필요할 것 같다.